클러스터는 인덱스를 최대 몇 개까지 생성할 수 있을까?
하나의 샤드 크기는 과연 얼마가 적당한가?
ElasticSearch로 서비스를 운영하고 있다면, 모두가 고민해봤을만한 주제이다.
시간이 지날 수록 데이터의 크기는 점점 커지고, 서비스는 살아있는 생물 같아서 관심을 주지 않으면 금방 엉망이 되어 버진다.
현재 서비스가 월활하게 된다고 해서 앞으로도 서비스가 월활하게 될것이라는 보장은 없다.
데이터가 계속 증가할 수 있기 때문에, 항상 최적화를 위해 고민해야 한다는 것이다.
운영 중에 샤드의 개수를 수정해도 되는가?
원칙적으로 클러스터를 운영중에 인덱스의 샤드 개수를 수정하는 것은 불가능하다.
하지만, 서비스를 운영하다보면, 데이터의 크기가 점점 더 커지고 너무 많은 데이터가 쌓이면, 샤드의 부하가 발생할 수 있다. 그러하니, 데이터의 크기가 최대 얼마까지 증가할 것인지를 사전에 잘 계산해서 최초 인덱스를 생성할 때, 샤드의 개수를 신중하게 결정해야 한다.
ElasticSearch에는 2 종류의 샤드가 존재한다.
Primary Shard와 Replica Shard이다.
Primary Shard는 실질적인 CRUD를 제공하는 샤드로 핵심적인 요소이다.
Replica Shard는 기본적으로 장애 복구를 위해 존재한다. 그러나, Primary와 동일한 데이터를 가지고 있기 때문에, 평상시에는 읽기 분산에도 활용이 된다.
- Number_of_shards : Primary Shard의 개수를 설정
- Number_of_replicas : Replica Shard의 개수를 설정
실제 운영 예제
시간이 흘러 인덱스에 총 1억건의 데이터가 색인되었다고 가정해보자,
Pramary Shard가 5개인 경우, 각 샤드는 2천만건의 데이터를 분산해서 갖게 될 것이다.
이 경우, 하나의 1개의 샤드에 데이터가 2천만건으로 많아져서 처음보다 검색 기능이 떨어지게 된다.
그러면, 노드를 추가해서 프라이머리 샤드를 5 -> 10개로 변경하면 될 것같지만,
프라이머리 샤드는 변경이 불가능하다. (자세한 내용은 루씬을 학습)
그럼에도 프라이머리 샤드의 개수를 변경해야 하는 경우?
새로운 인덱스를 생성하고 전체 재색인을 진행해야 한다.
Replica 샤드의 복제본 수, 얼마가 적당한가?
Replica 샤드의 복제본 수는 운영중에도 얼마든지 변경이 가능하다.
레플리카 샤드는 기존 프라이머리 샤드에서 단순히 복제만 하면 되기 때문이다.
일반적으로 장애가 발생했을때 빠른 복구를 위해서 1개 이상의 복제본 세트를 사용하는 것이 좋다.
장애 복구나 읽기 성능 향상을 위해 레플리카를 많이 사용하게 되지만, 이때 주의해야 할점이 있다.
너무 많은 복제본이 존재할 경우, 자칫 전체적인 "색인 성능의 저하"로 이어질 수도 있다.
이유는, 레플리카도 프라이머리와 동일한 검색 결과를 보장해야 하기 때문에, 모든 레플리카 샤드에도 데이터가 전송되어야 하기 때문이다.
따라서, 읽기 분산이 중요한 경우에는 색인 성능을 일부 포기하고 레플리카 세트 수를 늘리는것이 좋고,
빠른 색인이 중요한 경우에는 읽기 분산을 포기하고 레플리카 세트 수를 최소화 하는것이 좋다.
그런데, 위에서 말했던것 처럼 복제본의 수는 운영중에라도 변경이 가능하다.
따라서, 최초 서비스를 오픈할때는 복제본의 수를 최소화 해서 서비스 운영을 시작하는것이 좋다.
이후 모니터링을 하여 탄력적으로 복제본 수를 조절해 하나는것을 추천한다.
최소는 1개의 레플리카 세트(장애 대응)
클러스터에서 운영 가능한 최대 샤드 수?
ElasticSearch에서 운영 가능한 전체 샤드 수는 제한이 있을까?
결론부터 보자면, 샤드 수에 제한은 없다.
이론상 클러스터에 인덱스가 무한대로 생성될 수 있기 때문이다.
하지만, 개별 인덱스를 생성할때 설정 가능한 샤드의 수는 현재 1024개로 제한되어 있다.
적절한 샤드 크기는 얼마일까?
정해진 공식은 없지만, ElasticSearch에서는 다양한 사례를 통해 1개의 샤드가 물리적으로 50GB를 넘지 않도록 권장한다.
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/size-your-shards.html
데이터 기반으로 샤드수를 정한다면, 어느정도 미래를 고려해서 충분히 계산해보고 고민해야 한다.
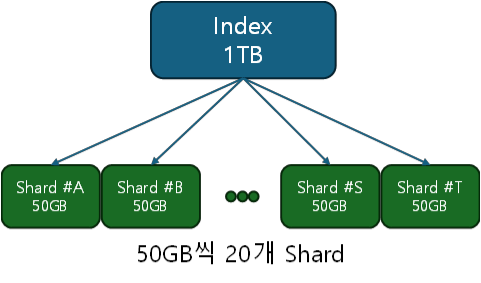
샤드의 개수가 얼마로 나뉘면 좋을지 가정해보자.
인덱스가 큰 데이터(400GB)를 가지는 경우,
Case1) 2개의 샤드로 분산하는 경우
- 각 샤드당 200GB의 크기이다, 이경우 복구를 위한 네트워크 비용이 너무 많이 발생하게 된다.
Case2) 400개의 샤드로 분산하는 경우
- 각 샤드당 1GB의 크기이다. 이 경우 데이터 복구는 수월하지만, 마스터 노드의 부하와 많은 리소스의 낭비를 가져올 것이다.
결론 : 하나의 샤드가 50GB정도로 가정하면, 샤드수는 8개면 충분할 것이다.
미래에 데이터가 일부 추가 되더라도 무난할것이다.
인덱스가 작은 데이터(1GB)를 가지는 경우,
Case1) ElasticSearch의 기본 설정이 5개의 샤드이다. 이보다 줄이는 것은 권장하지 않음.
Case2) 100개의 샤드로 분산하는 경우
- 각 샤드당 10MB, 이경우 심한 리소스 낭비
결론 : 기본설정 5개 샤드.
클러스터에 샤드수가 많이 존재할 경우
모든 샤드는 마스터 노드에서 관리된다.
그러므로 샤드가 많아질수록 마스터 노드의 부하도 함께 증가한다.
관리해야 하는 정보의 양도 많아지기 때문이다.
(관리 데이터를 모두 메모리에 올려서 제공한다 )
만약 마스터 노드가 장애가 발생한다면, 클러스터 전체가 마비되는 사고로 번질 수 있다.
샤드의 물리적인 크기와 복구 시간
장애가 발생하면 샤드 단위로 복구를 수행하기 때문에, 마스터 노드 입장에서는 샤드가 가지고 있는 데이터 건수보다, 데이터의 크기가 중요하다.
장애가 발생하면, 레플리카 샤드가 프라이머리로 전환되어 서비스 되며, 그와 동시에 프라이머리 샤드와 동인한 샤드가 물리적으로 다른 장비에서 레플리카 샤드로 새롭게 구성된다.
그리고 시간이 지나 장애가 발생한 노드가 복구가 되면, 복구된 노드로 일부 샤드들이 네트워크를 통해 이동한다. 이러한 과정을 통해 전체적인 클러스터의 균형을 맞춘다.
책 : 엘라스틱서치 실무 가이드 (위키북스)
https://www.elastic.co/kr/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
'IT Knowledge > ElasticSearch' 카테고리의 다른 글
| Elasticsearch 안정적인 클러스터 운영 노하우 (32) | 2024.08.06 |
|---|---|
| ElasticSearch 대용량 처리를 위한 시스템 최적화. (0) | 2024.08.06 |
| ElasticSearch Cluster 구성 고려사항 (0) | 2024.05.28 |
| ElasticSearch 인덱스(Index)란? (0) | 2024.05.28 |
| ElasticSearch를 구성하는 개념 (0) | 2024.05.27 |



댓글